













[ad_1]
Operating any scalable distributed platform calls for a dedication to reliability, to make sure prospects have what they want after they want it. The dependencies may very well be relatively intricate, particularly with a platform as huge as Roblox. Constructing dependable providers signifies that, whatever the complexity and standing of dependencies, any given service won’t be interrupted (i.e. extremely accessible), will function bug-free (i.e. excessive high quality) and with out errors (i.e. fault tolerance).
Why Reliability Issues
Our Account Identification crew is dedicated to reaching larger reliability, for the reason that compliance providers we constructed are core elements to the platform. Damaged compliance can have extreme penalties. The price of blocking Roblox’s pure operation could be very excessive, with further sources essential to get well after a failure and a weakened person expertise.
The everyday strategy to reliability focuses totally on availability, however in some instances phrases are blended and misused. Most measurements for availability simply assess whether or not providers are up and operating, whereas facets comparable to partition tolerance and consistency are generally forgotten or misunderstood.
In accordance with the CAP theorem, any distributed system can solely assure two out of those three facets, so our compliance providers sacrifice some consistency with the intention to be extremely accessible and partition-tolerant. Nonetheless, our providers sacrificed little and located mechanisms to attain good consistency with cheap architectural adjustments defined under.
The method to succeed in larger reliability is iterative, with tight measurement matching steady work with the intention to stop, discover, detect and repair defects earlier than incidents happen. Our crew recognized robust worth within the following practices:
- Proper measurement – Construct full observability round how high quality is delivered to prospects and the way dependencies ship high quality to us.
- Proactive anticipation – Carry out actions comparable to architectural evaluations and dependency threat assessments.
- Prioritize correction – Carry larger consideration to incident report decision for the service and dependencies which are linked to our service.
Constructing larger reliability calls for a tradition of high quality. Our crew was already investing in performance-driven improvement and is aware of the success of a course of relies upon upon its adoption. The crew adopted this course of in full and utilized the practices as a typical. The next diagram highlights the elements of the method:
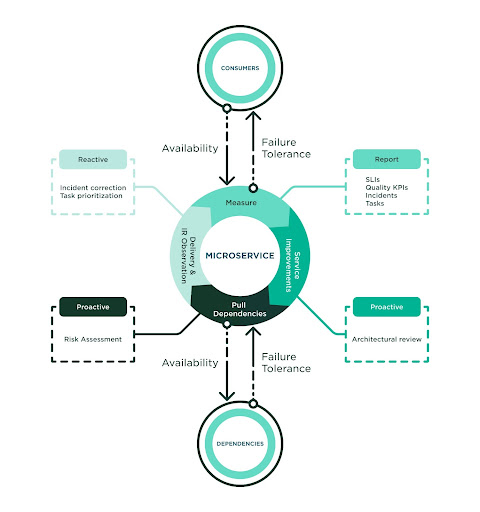
The Energy of Proper Measurement
Earlier than diving deeper into metrics, there’s a fast clarification to make relating to Service Degree measurements.
- SLO (Service Degree Goal) is the reliability goal that our crew goals for (i.e. 99.999%).
- SLI (Service Degree Indicator) is the achieved reliability given a timeframe (i.e. 99.975% final February).
- SLA (Service Degree Settlement) is the reliability agreed to ship and be anticipated by our shoppers at a given timeframe (i.e. 99.99% per week).
The SLI ought to mirror the supply (no unhandled or lacking responses), the failure tolerance (no service errors) and high quality attained (no surprising errors). Subsequently, we outlined our SLI because the “Success Ratio” of profitable responses in comparison with the overall requests despatched to a service. Profitable responses are these requests that had been dispatched in time and kind, that means no connectivity, service or surprising errors occurred.
This SLI or Success Ratio is collected from the shoppers’ perspective (i.e., shoppers). The intention is to measure the precise end-to-end expertise delivered to our shoppers in order that we really feel assured SLAs are met. Not doing so would create a false sense of reliability that ignores all infrastructure issues to attach with our shoppers. Just like the buyer SLI, we gather the dependency SLI to trace any potential threat. In observe, all dependency SLAs ought to align with the service SLA and there’s a direct dependency with them. The failure of 1 implies the failure of all. We additionally observe and report metrics from the service itself (i.e., server) however this isn’t the sensible supply for prime reliability.
Along with the SLIs, each construct collects high quality metrics which are reported by our CI workflow. This observe helps to strongly implement high quality gates (i.e., code protection) and report different significant metrics, comparable to coding customary compliance and static code evaluation. This matter was beforehand coated in one other article, Constructing Microservices Pushed by Efficiency. Diligent observance of high quality provides up when speaking about reliability, as a result of the extra we put money into reaching glorious scores, the extra assured we’re that the system won’t fail throughout opposed situations.
Our crew has two dashboards. One delivers all visibility into each the Customers SLI and Dependencies SLI. The second exhibits all high quality metrics. We’re engaged on merging every little thing right into a single dashboard, in order that the entire facets we care about are consolidated and able to be reported by any given timeframe.
Anticipate Failure
Doing Architectural Critiques is a elementary a part of being dependable. First, we decide whether or not redundancy is current and if the service has the means to outlive when dependencies go down. Past the everyday replication concepts, most of our providers utilized improved twin cache hydration strategies, twin restoration methods (comparable to failover native queues), or information loss methods (comparable to transactional assist). These matters are in depth sufficient to warrant one other weblog entry, however finally one of the best suggestion is to implement concepts that think about catastrophe eventualities and decrease any efficiency penalty.
One other necessary facet to anticipate is something that would enhance connectivity. Which means being aggressive about low latency for shoppers and getting ready them for very excessive site visitors utilizing cache-control strategies, sidecars and performant insurance policies for timeouts, circuit breakers and retries. These practices apply to any consumer together with caches, shops, queues and interdependent shoppers in HTTP and gRPC. It additionally means bettering wholesome alerts from the providers and understanding that well being checks play an necessary position in all container orchestration. Most of our providers do higher alerts for degradation as a part of the well being test suggestions and confirm all important elements are useful earlier than sending wholesome alerts.
Breaking down providers into important and non-critical items has confirmed helpful for specializing in the performance that issues essentially the most. We used to have admin-only endpoints in the identical service, and whereas they weren’t used typically they impacted the general latency metrics. Shifting them to their very own service impacted each metric in a optimistic path.
Dependency Danger Evaluation is a vital instrument to determine potential issues with dependencies. This implies we determine dependencies with low SLI and ask for SLA alignment. These dependencies want particular consideration throughout integration steps so we commit further time to benchmark and take a look at if the brand new dependencies are mature sufficient for our plans. One good instance is the early adoption we had for the Roblox Storage-as-a-Service. The mixing with this service required submitting bug tickets and periodic sync conferences to speak findings and suggestions. All of this work makes use of the “reliability” tag so we will shortly determine its supply and priorities. Characterization occurred typically till we had the arrogance that the brand new dependency was prepared for us. This further work helped to drag the dependency to the required degree of reliability we anticipate to ship appearing collectively for a typical objective.
Carry Construction to Chaos
It’s by no means fascinating to have incidents. However after they occur, there’s significant info to gather and be taught from with the intention to be extra dependable. Our crew has a crew incident report that’s created above and past the everyday company-wide report, so we concentrate on all incidents whatever the scale of their impression. We name out the foundation trigger and prioritize all work to mitigate it sooner or later. As a part of this report, we name in different groups to repair dependency incidents with excessive precedence, observe up with correct decision, retrospect and search for patterns that will apply to us.
The crew produces a Month-to-month Reliability Report per Service that features all of the SLIs defined right here, any tickets we’ve got opened due to reliability and any attainable incidents related to the service. We’re so used to producing these stories that the following pure step is to automate their extraction. Doing this periodic exercise is necessary, and it’s a reminder that reliability is continually being tracked and regarded in our improvement.

Our instrumentation contains customized metrics and improved alerts in order that we’re paged as quickly as attainable when identified and anticipated issues happen. All alerts, together with false positives, are reviewed each week. At this level, sprucing all documentation is necessary so our shoppers know what to anticipate when alerts set off and when errors happen, after which everybody is aware of what to do (e.g., playbooks and integration pointers are aligned and up to date typically).
Finally, the adoption of high quality in our tradition is essentially the most important and decisive think about reaching larger reliability. We are able to observe how these practices utilized to our day-to-day work are already paying off. Our crew is obsessive about reliability and it’s our most necessary achievement. We’ve got elevated our consciousness of the impression that potential defects might have and after they may very well be launched. Providers that applied these practices have constantly reached their SLOs and SLAs. The reliability stories that assist us observe all of the work we’ve got been doing are a testomony to the work our crew has completed, and stand as invaluable classes to tell and affect different groups. That is how the reliability tradition touches all elements of our platform.
The street to larger reliability isn’t a straightforward one, however it’s mandatory if you wish to construct a trusted platform that reimagines how folks come collectively.
Alberto is a Principal Software program Engineer on the Account Identification crew at Roblox. He’s been within the sport business a very long time, with credit on many AAA sport titles and social media platforms with a powerful concentrate on extremely scalable architectures. Now he’s serving to Roblox attain development and maturity by making use of finest improvement practices.
[ad_2]
Source link

