













[ad_1]
Facial features is a vital step in Roblox’s march in direction of making the metaverse part of individuals’s day by day lives by way of pure and plausible avatar interactions. Nevertheless, animating digital 3D character faces in actual time is a gigantic technical problem. Regardless of quite a few analysis breakthroughs, there are restricted business examples of real-time facial animation functions. That is significantly difficult at Roblox, the place we assist a dizzying array of person gadgets, real-world circumstances, and wildly inventive use circumstances from our builders.


On this put up, we’ll describe a deep studying framework for regressing facial animation controls from video that each addresses these challenges and opens us as much as quite a lot of future alternatives. The framework described on this weblog put up was additionally introduced as a discuss at SIGGRAPH 2021.
Facial Animation
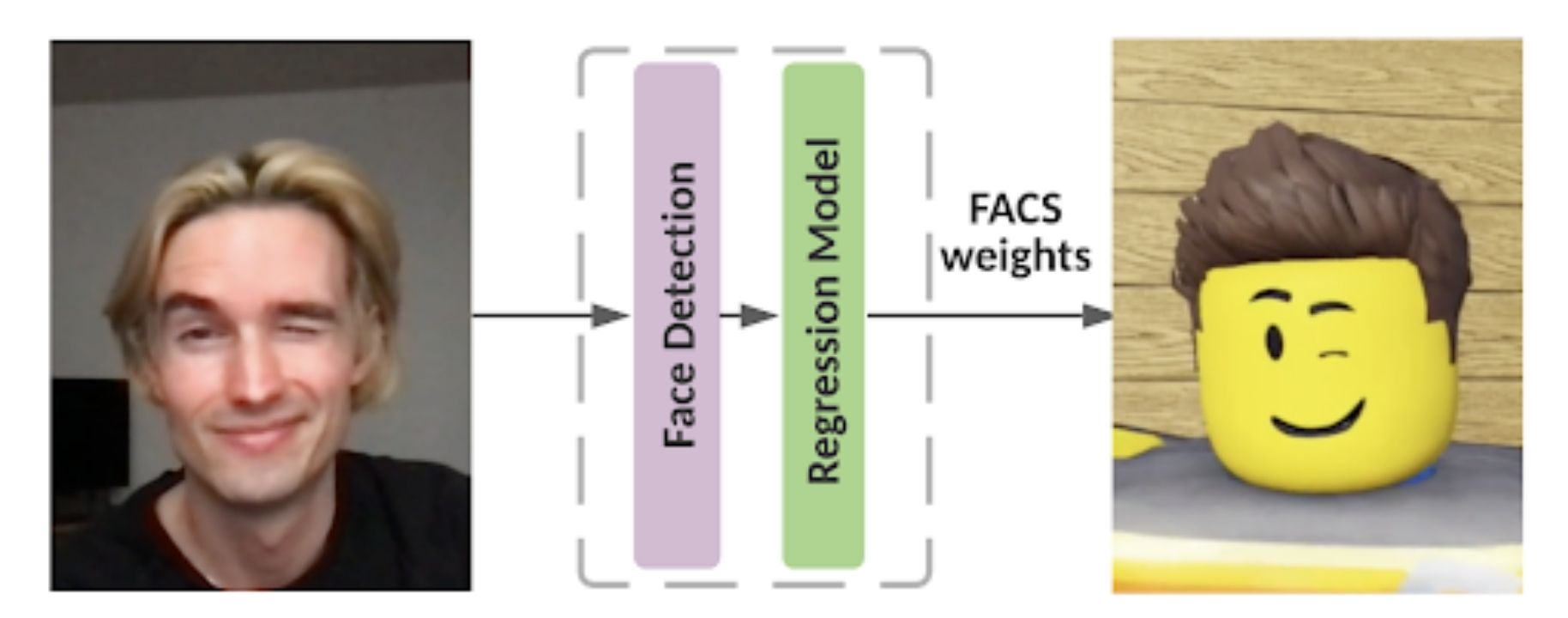
There are numerous choices to manage and animate a 3D face-rig. The one we use is known as the Facial Motion Coding System or FACS, which defines a set of controls (primarily based on facial muscle placement) to deform the 3D face mesh. Regardless of being over 40 years previous, FACS are nonetheless the de facto commonplace as a result of FACS controls being intuitive and simply transferable between rigs. An instance of a FACS rig being exercised could be seen under.

Technique
The thought is for our deep learning-based technique to take a video as enter and output a set of FACS for every body. To realize this, we use a two stage structure: face detection and FACS regression.
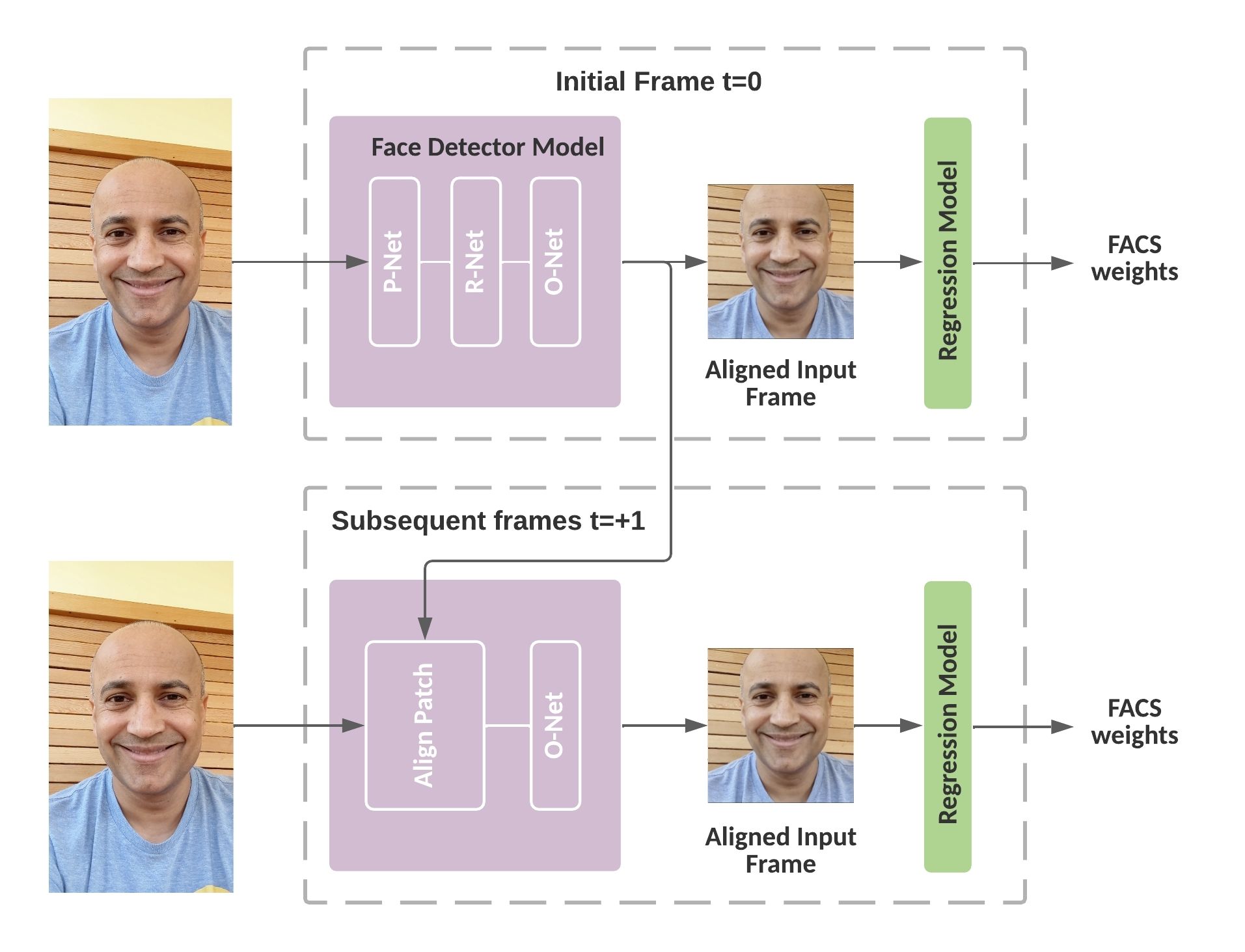
Face Detection
To realize the most effective efficiency, we implement a quick variant of the comparatively well-known MTCNN face detection algorithm. The unique MTCNN algorithm is kind of correct and quick however not quick sufficient to assist real-time face detection on most of the gadgets utilized by our customers. Thus to resolve this we tweaked the algorithm for our particular use case the place as soon as a face is detected, our MTCNN implementation solely runs the ultimate O-Web stage within the successive frames, leading to a mean 10x speed-up. We additionally use the facial landmarks (location of eyes, nostril, and mouth corners) predicted by MTCNN for aligning the face bounding field previous to the following regression stage. This alignment permits for a good crop of the enter photos, decreasing the computation of the FACS regression community.
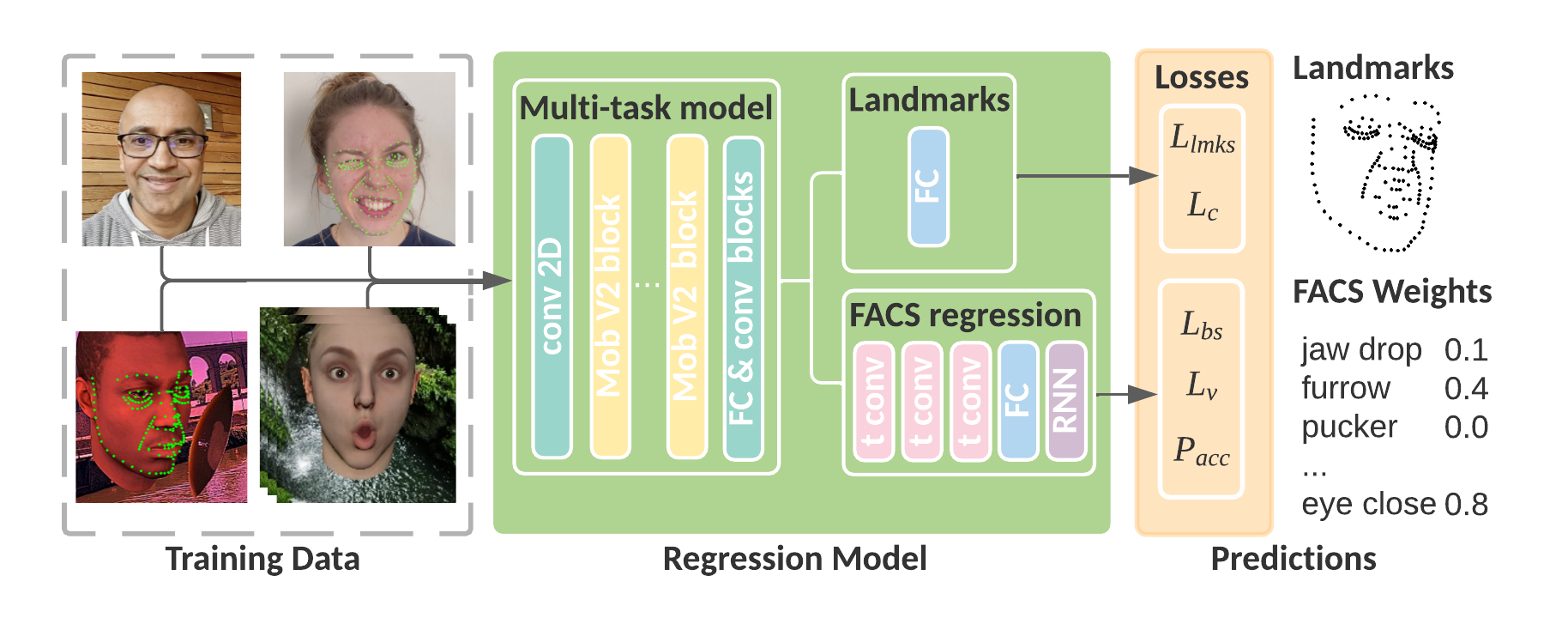
FACS Regression
Our FACS regression structure makes use of a multitask setup which co-trains landmarks and FACS weights utilizing a shared spine (generally known as the encoder) as function extractor.
This setup permits us to reinforce the FACS weights realized from artificial animation sequences with actual photos that seize the subtleties of facial features. The FACS regression sub-network that’s skilled alongside the landmarks regressor makes use of causal convolutions; these convolutions function on options over time versus convolutions that solely function on spatial options as could be discovered within the encoder. This permits the mannequin to study temporal features of facial animations and makes it much less delicate to inconsistencies resembling jitter.
Coaching
We initially practice the mannequin for under landmark regression utilizing each actual and artificial photos. After a sure variety of steps we begin including artificial sequences to study the weights for the temporal FACS regression subnetwork. The artificial animation sequences have been created by our interdisciplinary crew of artists and engineers. A normalized rig used for all of the completely different identities (face meshes) was arrange by our artist which was exercised and rendered mechanically utilizing animation information containing FACS weights. These animation information have been generated utilizing traditional pc imaginative and prescient algorithms working on face-calisthenics video sequences and supplemented with hand-animated sequences for excessive facial expressions that have been lacking from the calisthenic movies.
Losses
To coach our deep studying community, we linearly mix a number of completely different loss phrases to regress landmarks and FACS weights:
- Positional Losses. For landmarks, the RMSE of the regressed positions (Llmks ), and for FACS weights, the MSE (Lfacs ).
- Temporal Losses. For FACS weights, we cut back jitter utilizing temporal losses over artificial animation sequences. A velocity loss (Lv ) impressed by [Cudeiro et al. 2019] is the MSE between the goal and predicted velocities. It encourages general smoothness of dynamic expressions. As well as, a regularization time period on the acceleration (Lacc ) is added to cut back FACS weights jitter (its weight saved low to protect responsiveness).
- Consistency Loss. We make the most of actual photos with out annotations in an unsupervised consistency loss (Lc ), just like [Honari et al. 2018]. This encourages landmark predictions to be equivariant underneath completely different picture transformations, bettering landmark location consistency between frames with out requiring landmark labels for a subset of the coaching photos.
Efficiency
To enhance the efficiency of the encoder with out decreasing accuracy or rising jitter, we selectively used unpadded convolutions to lower the function map dimension. This gave us extra management over the function map sizes than would strided convolutions. To take care of the residual, we slice the function map earlier than including it to the output of an unpadded convolution. Moreover, we set the depth of the function maps to a a number of of 8, for environment friendly reminiscence use with vector instruction units resembling AVX and Neon FP16, and leading to a 1.5x efficiency increase.
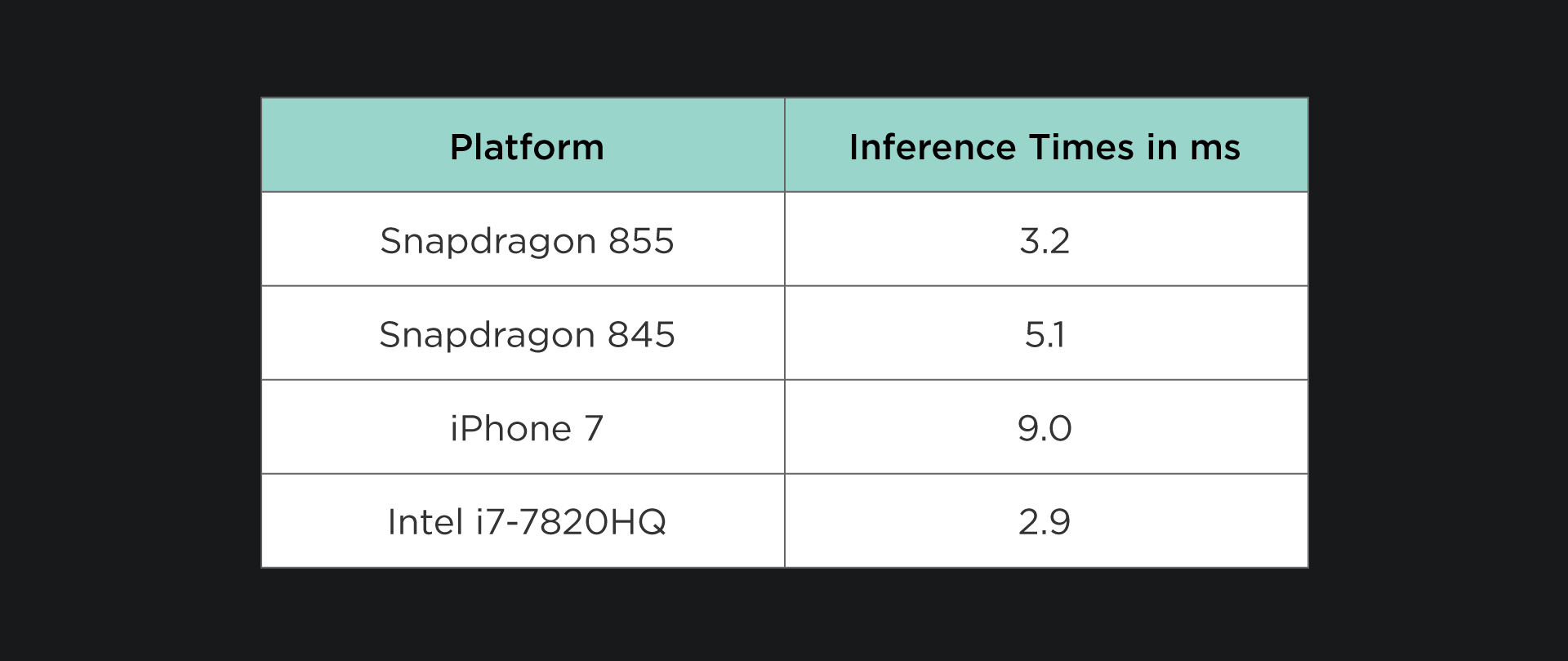
Our ultimate mannequin has 1.1 million parameters, and requires 28.1million multiply-accumulates to execute. For reference, vanilla Mobilenet V2 (which our structure is predicated on) requires 300 million multiply-accumulates to execute. We use the NCNN framework for on-device mannequin inference and the one threaded execution time(together with face detection) for a body of video are listed within the desk under. Please notice an execution time of 16ms would assist processing 60 frames per second (FPS).
What’s Subsequent
Our artificial information pipeline allowed us to iteratively enhance the expressivity and robustness of the skilled mannequin. We added artificial sequences to enhance responsiveness to missed expressions, and in addition balanced coaching throughout different facial identities. We obtain high-quality animation with minimal computation due to the temporal formulation of our structure and losses, a rigorously optimized spine, and error free ground-truth from the artificial information. The temporal filtering carried out within the FACS weights subnetwork lets us cut back the quantity and dimension of layers within the spine with out rising jitter. The unsupervised consistency loss lets us practice with a big set of actual information, bettering the generalization and robustness of our mannequin. We proceed to work on additional refining and bettering our fashions, to get much more expressive, jitter-free, and sturdy outcomes.
In case you are taken with engaged on related challenges on the forefront of real-time facial monitoring and machine studying, please take a look at a few of our open positions with our crew.
[ad_2]
Source link

